基于Spark和Power BI的中文词频统计
Word Count 是学习Spark开发的一个经典案例,类似于其他编程语言中的Hello World程序。但这个例子是基于英文的,英文断句分词是一件比较容易的事情,一般都是以空格为分隔符进行分词。但对于中文来说,事情就复杂了。
分词
分词(Word Segmentation)是属于自然语言处理(Natural Language Processing)的范畴。
分词是将连续的
字序列按照一定的规范重新组合成词序列的过程。
例如:
I am a student → I / am / a / student
我是一个学生 → 我/ 是/ 一个/ 学生
分词在很多领域有着非常重要的作用,比如:
- 搜索引擎
- 机器翻译
- 语音合成
- 自动摘要
中文分词
中文分词很难。首先,与西方文字不同,中文的单词之间并没有空格作为分隔。在中国古典文献中,甚至连标点符号也没有。其次中文博大精深,多音字、歧义、网络新词等问题让中文分词更难。你可以从下面的例句中感受一二。
- 严守一把手机关了
- 吃饭了吗?饭吃了吗
- 中国队大胜韩国队,中国队大败韩国队
中文分词算法大概可以分为以下三大类:
- 基于
词典的方法。它按照一定策略将待分析的中文序列与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。这类分词器通常会加入一些启发式规则,比如“正向/反向最大匹配”,“长词优先”等。 - 基于
统计以及机器学习的方法。它是基于人工标注的词性和统计特征,对中文进行建模,根据观测到的数据(标注好的语料)对模型参数进行训练,在分词阶段再通过模型计算各种分词出现的概率,将概率最大的分词结果作为最终结果。常见的序列标注模型有隐马尔科夫模型(Hidden Markov Model,HMM)和条件随机场模型(Conditional Random Field,CRF)。这类分词算法能很好处理歧义和未登录词问题,效果比前一类效果好,但是需要大量的人工标注数据,以及较慢的分词速度。 - 基于
语义的方法。它通过让计算机模拟人对句子的理解,达到识别词的效果,由于汉语语义的复杂性,难以将各种语言信息组织成机器能够识别的形式,目前这种分词系统还处于试验阶段。
IK Analyzer
在 NLP 学术界,分词的问题从上个世纪 80 年代就已经开始探索,目前工程领域已有很多可用的分词器。
下面是一张常见的分词器列表: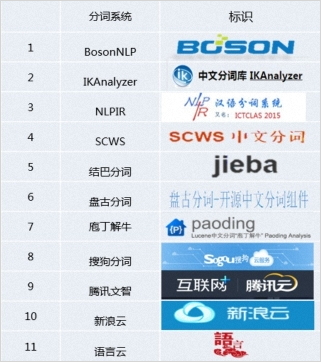
本文中,我将采用IK Analyzer这个中文分词器,它是用基于词典的方法来对中文进行分词。IK采用 JAVA 开发,对 Lucene 和 Elasticsearch 支持较好,因而得到了比较广泛的使用。该分词器可以实现英文单词、中文单词的切分。IK还支持用户自定义词典以及热更新用户词典,对搜索比较友好。
IK Analyzer的作者为林良益(linliangyi2007@gmail.com),项目网站为http://code.google.com/p/ik-analyzer/。
使用Spark进行词频统计
Spark是一个用于集群计算的通用框架,它扩展了广泛使用的MapReduce计算模型。
经典的Word Count
作为入门级的案例,一个典型的Word Count程序是这样的:
1 | object WordCount { |
上面的Scala代码无需过多的解释,非常清晰、简单。
支持中文的Word Count
下面是结合了IK分词器的Word Count代码:
1 | object Main extends App { |
在这里我使用了金庸的射雕三部曲作为词频统计的目标。原始的文件是基于gb2312编码的,所以在读入文件的时候需要指定编码。当然,我们也可以事先将其存储为UTF-8的编码格式。
在第12行中,我们使用IK Analyzer对每一行的文本进行分词。其中,IKTokenizer构造函数中传入的true表示使用最大长度切分。
在第17行中,我们把单字过滤掉;第18行表示按照单词统计的值进行倒序排列;第19行将统计结果转成csv格式的数据为后续的可视化做准备。
整个工程的源码可以在我的GitHub上找到:https://github.com/johnnyqian/spark-word-count-with-powerbi
使用Power BI对分词结果进行可视化
上述的Spark程序运行完成后会输出一个csv文件,以《射雕英雄传》为例:
| Name | Count |
|---|---|
| 郭靖 | 4786 |
| 黄蓉 | 3481 |
| 欧阳 | 1247 |
| 洪七公 | 996 |
| 说道 | 982 |
| 笑道 | 908 |
| 黄药师 | 814 |
| … | … |
从结果中,我们一下子就能发现整本书的几个核心人物,是不是很有意思?但是仅仅用表格展示还不够好,我希望能更加直观的看到词频的差别。
Power BI
微软的Power BI是一个非常强大的数据可视化工具,它提供的一个Word Cloud插件非常符合我的预期效果。
Power BI 有桌面版、移动版和网页版,网页版使用起来比较方便。我们登录到Power BI的网页版,导入我们的csv数据: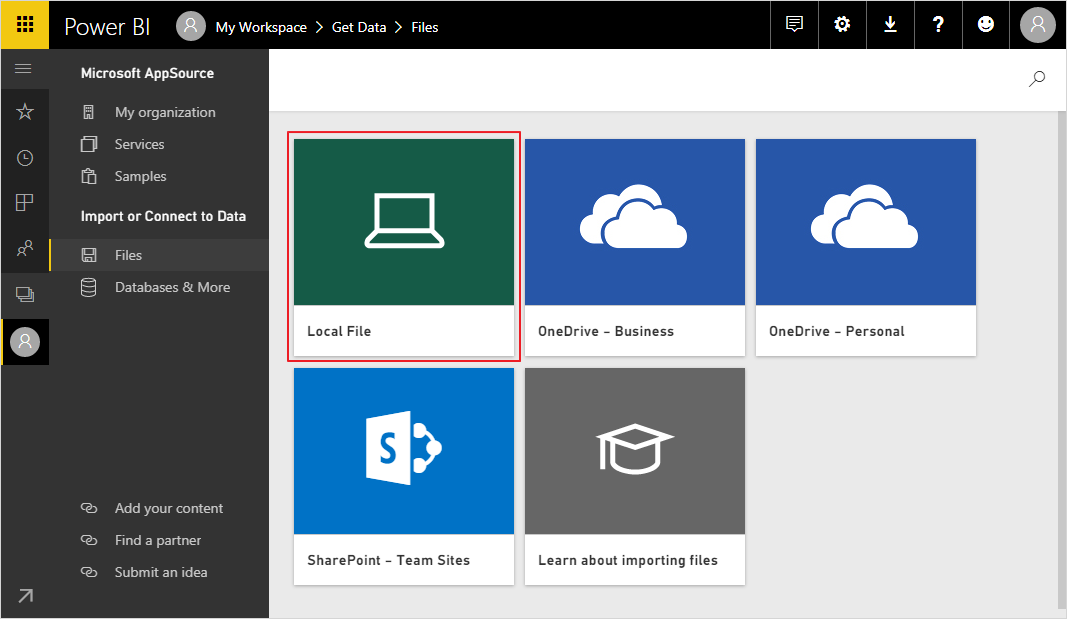
Power BI需要使用公司或组织的邮箱才能注册,一般的邮箱不允许注册。
数据导入成功后,我们来到报表创建页面,选择右侧数据集中的列,Power BI默认会用柱状图来展示: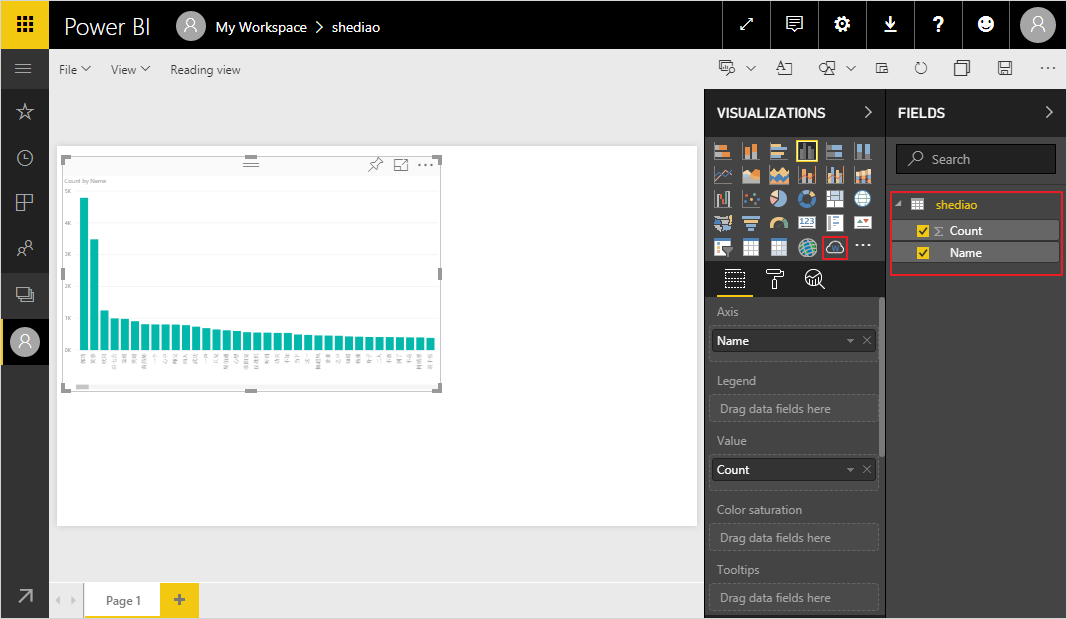
然后,导入下载好的Word Cloud插件,点击这个插件,数据就会以Word Cloud的形式展示,这种展示形式具有极强的视觉效果。词频越高的词汇,其字体会越大。你还可以对这个插件做一些细微的调整,比如字体的颜色、旋转的角度、背景、边框等等。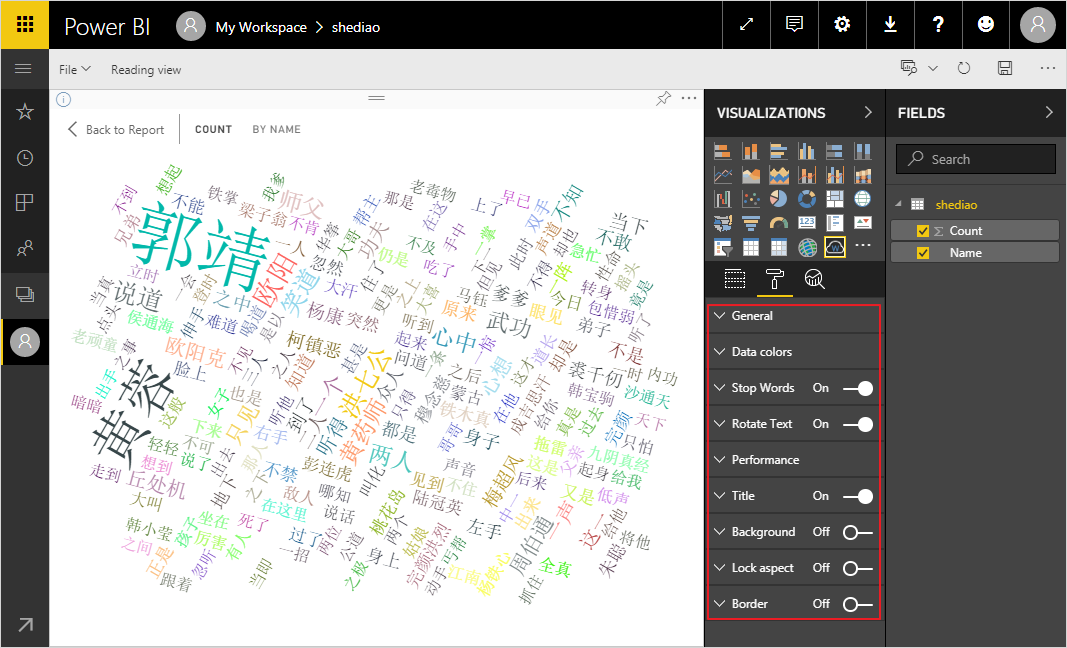
当然Power BI还有更强大的功能,有兴趣的可以自己慢慢探索。
金庸射雕三部曲词频统计结果
依次对另外两部小说做同样的处理,我们得到了如下的结果。
射雕英雄传

神雕侠侣

倚天屠龙记

总结
本文在Spark中结合IK分词器对长篇中文小说进行了词频统计,然后使用Power BI对统计结果进行了可视化,算是一种有趣的有益探索。但最后的结果也有一些不足之处。比如分词中,“欧阳”不应该出现。可以想见,应该统计的词语是“欧阳锋”和“欧阳克”,这就需要我们对IK分词器的词典以及参数做出相应的调整。