字符编码与字符集 — Unicode
当计算机应用到世界各地时,为了适应当地的语言和字符,各个国家会与中国一样设计类似GB 2312/GBK/GB 18030等之类的编码方案。这会导致了一个非常麻烦的问题,就是一个文件可能因为编码问题而在其它国家的计算机中根本无法查看。这个世界需要一个统一的字符集。
UCS与Unicode
国际标谁化组织(ISO)最先开始着手解决这个问题。他们于1984年创立了ISO/IEC JTC1/SC2/WG2工作组,试图制定一份“通用字符集”(Universal Multiple-Octet Coded Character Set,简称UCS,中文译为通用多八位编码字符集),并最终制定了ISO 10646方案。该方案废弃了所有地区性的编码方案,并尝试把它们融合在一个统一的编码方案中。UCS包含了已知语言的所有字符。除了拉丁语、希腊语、斯拉夫语、希伯来语、阿拉伯语、亚美尼亚语、格鲁吉亚语,还包括中文、日文、韩文这样的方块文字,UCS还包括大量的图形、印刷、数学、科学符号。
而在1988年,Xerox、Apple等软件制造商成立了统一码联盟(The Unicode Consortium),并且开发了Unicode标准(The Unicode Standard)。
1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的统一字符集。于是,它们开始合并双方的工作成果,并为创立一个单一的统一字符集而协同工作。从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。两个项目至今仍都独立存在,并独立地公布各自的标准。不过由于Unicode这一名字比较好记,因而它使用得更为广泛。
Unicode伴随着通用字符集的标准而发展,同时也以书本的形式对外发表。Unicode至今仍在不断增修,每个新版本都加入更多新的字符。Unicode备受认可,并广泛地应用于计算机软件的国际化与本地化过程。很多新技术,如可扩展置标语言(Extensible Markup Language,XML)、Java编程语言以及现代的操作系统,都采用Unicode编码。
Unicode编码
Unicode 是一个伟大的创想,它给世界上所有的符号都给予了一个独一无二的编码或码位(Code Point)。Unicode包含1,114,112个码位,范围是0x00到0x10FFFF。码位使用数值表示,数值格式为:U+hhhh,其中每个h代表一个十六进制数字。Unicode 的所有码位组成了Unicode编码空间。在Unicode编码空间中,Unicode码位分为17组编排,每组称为一个平面(Plane),每个平面拥有65536个码位。如下表所示:
| 平面 | 始末码位值 | 中文名称 | 英文名称 |
|---|---|---|---|
| 0号平面 | U+0000 - U+FFFF | 基本多文种平面 | Basic Multilingual Plane,简称 BMP |
| 1号平面 | U+10000 - U+1FFFF | 多文种补充平面 | Supplementary Multilingual Plane,简称 SMP |
| 2号平面 | U+20000 - U+2FFFF | 表意文字补充平面 | Supplementary Ideographic Plane,简称 SIP |
| 3号平面 | U+30000 - U+3FFFF | 表意文字第三平面 | Tertiary Ideographic Plane,简称 TIP |
| 4号平面-13号平面 | U+40000 - U+DFFFF | (尚未使用) | |
| 14号平面 | U+E0000 - U+EFFFF | 特别用途补充平面 | Supplementary Special-purpose Plane,简称 SSP |
| 15号平面 | U+F0000 - U+FFFFF | 保留作为 私人使用区(A 区) | Private Use Area-A,简称 PUA-A |
| 16号平面 | U+100000 - U+10FFFF | 保留作为 私人使用区(B 区) | Private Use Area-B,简称 PUA-B |
1-16号平面又称为
辅助平面。
Unicode 遵守已有的一些规则(即已经存在的、流行的地区性编码规则)把世界上所有的字符一一映射到码位中。被使用的码位,其值就是对应字符的Unicode编码值。例如, U+0041 表示拉丁字母 “A”;U+40000 由于没使用,则不表示任何字符。Unicode最新的版本为2019年5月公布的12.1.0,已收录超过13万个字符,约占12%的编码空间。
Unicode编码分布
下面的这张图更直观的显示了当前Unicode编码的分布状况。
上图中每个小方块代表 256 个码位, 每个大的方块代表一个平面(65536 个码位),一共17个平面。
- 白色的方块代表未被分配的码位
- 蓝色的方块代表已被分配的码位
- 绿色的方块是私人使用区
- 红色的方块是代理码位(UTF-16 surrogates)
从图上可以看到,已被分配的码位集中在BMP平面(0号平面)以及1、2号辅助平面。我们来仔细看下BMP平面的编码分布。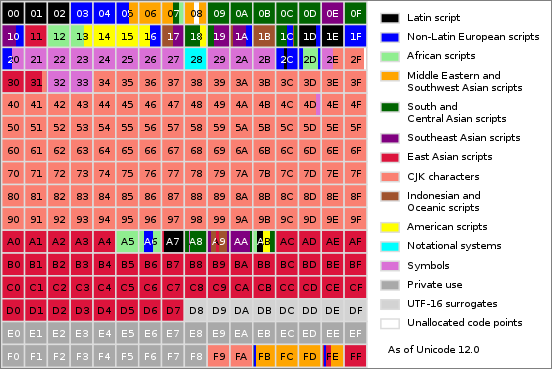 Unicode基本多文种平面的示意图
Unicode基本多文种平面的示意图
BMP平面包含了最基本的字符集,有基本拉丁文、西欧字符、非洲字符以及占据一大半编码空间的中日韩字符等。BMP平面中的很多码位是直接参考其它早期编码方案的。例如,BMP平面前128个字符的码位与ASCII是一致的,显然这对兼容性是很有好处的。
中日韩统一表意文字
中日韩统一表意文字(CJK Unified Ideographs),也称统一汉字(Unihan),目的是要把来自中文、日文、韩文、越南文、壮文、琉球文中,起源相同、本义相同、形状一样或稍异的表意文字,在ISO 10646及Unicode标准中赋予相同的编码。
1978年日本基于ISO 2022,制订了全世界最早的汉字编码JIS C 6226。1980年代,中国大陆、台湾、韩国则各自制订了自己的规范。这些规范彼此之间并无关系。1991年,东亚各国希望能以一致的方式处理文字。基于中国与Unicode联盟的提议,ISO 10646和Unicode成立了中日韩联合研究小组。中日韩联合研究小组将基于各国的汉字编码,独自定义定规范、制作ISO 10646和Unicode的统一汉字编码。1993年5月,正式制订了最初的中日韩统一表意文字,位于U+4E00–U+9FFF这个区域,共20,902个字。后续又陆陆续续增加了很多新的CJK字符,主要的增项如下表所示:
| ISO 10646 版本 | Unicode 版本 | 新增 | 置放平面 | 字数 | 累计字数 |
|---|---|---|---|---|---|
| 1993 | 1.0 | 中日韩统一表意文字 | 基本多文种平面 | 20,902 | 20,915 |
| 2000 | 3.0 | 中日韩统一表意文字扩展A区 | 基本多文种平面 | 6,582 | 27,497 |
| 2001 | 3.1 | 中日韩统一表意文字扩展B区 | 第二辅助平面 | 42,711 | 70,208 |
| 2003第五修订版 | 5.2 | 中日韩统一表意文字扩展C区 | 第二辅助平面 | 4,149 | 74,395 |
| 2010 | 6.0 | 中日韩统一表意文字扩展D区 | 第二辅助平面 | 222 | 74,617 |
| 2015 | 8.0 | 中日韩统一表意文字扩展E区 | 第二辅助平面 | 5,762 | 80,389 |
| 2017 | 10.0 | 中日韩统一表意文字扩展F区 | 第二辅助平面 | 7,473 | 87,883 |
Unicode的实现方式
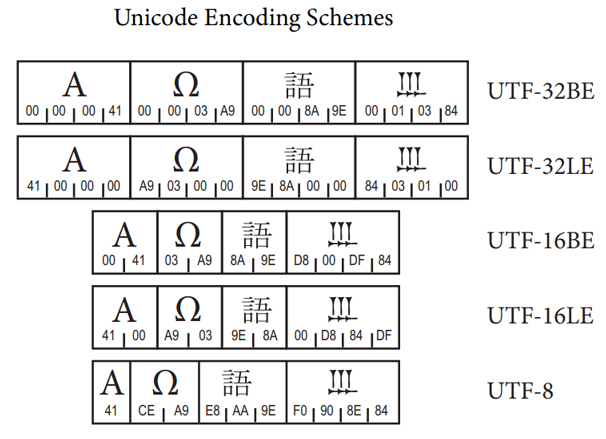
Unicode的存储与传输方式不同于编码方式。一个字符的 Unicode编码是确定的。但是在实际存储或传输过程中,由于不同系统平台的设计,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。
UTF-32
UTF-32又称UCS-4是一种Unicode字符编码的方法,对每个Unicode字符都使用4个字节,因此存储效率比较低。但这种方法有其优点,最重要的一点就是可以在常数时间内定位字符串里的第N个字符,因为第N个字符从第4×Nth个字节开始。
UTF-16
尽管Unicode字符集非常大,但是实际上大多数人不会用到前65535个以外的字符。因此,就有了另外一种Unicode编码方式——UTF-16。UTF-16将0–65535范围内的字符编码成2个字节,如果真的需要表达那些很少使用的、超过这65535范围的Unicode字符(辅助平面的字符),则需要使用一些诡异的技巧来实现。
在BMP内,从U+D800到U+DFFF之间的码位区块,一共有0x800个(2的11次方,2048)码位是不映射到任何Unicode字符的。UTF-16就利用这个区块的码位来对辅助平面的字符进行编码。辅助平面中的码位从U+10000到U+10FFFF,共有0xFFFFF个(2的20次方,1,048,576)码位需要编码,需要20比特来表示。可以把这20比特分成2个10比特的字节:
- 高位的10比特的值(值的范围为0-0x3FF)加上
0xD800得到第一个码元称作高位代理(high surrogate),值的范围是0xD800-0xDBFF。由于高位代理比低位代理的值要小,为了避免混淆使用,Unicode标准现在称高位代理为前导代理(lead surrogates)。 - 低位的10比特的值(值的范围也是0-0x3FF)加上
0xDC00得到第二个码元称作低位代理(low surrogate),值的范围是0xDC00-0xDFFF。由于低位代理比高位代理的值要大,为了避免混淆使用,Unicode标准现在称低位代理为后尾代理(trail surrogates)。
总结上述算法,UTF-16的编码方法是:
- 如果字符编码U小于0x10000,也就是十进制的0到65535之内,则直接使用两字节表示;
- 如果字符编码U大于0x10000,由于Unicode编码范围最大为0x10FFFF,从0x10000到0x10FFFF之间共有0xFFFFF个编码,用U’表示从0-0xFFFFF之间的值,将其前10bit作为高位和16 bit的数值0xD800进行逻辑或操作,将后10 bit作为低位和0xDC00做逻辑或操作,这样组成的4个byte就构成了U的编码。
下表总结了编码规则,字母x、y表示可用编码的位。
| Unicode符号范围 (十六进制) | Unicode 码位 (二进制) | UTF-16编码 (二进制) |
|---|---|---|
| 0000 0000-0000 FFFF | xxxxxxxx xxxxxxxx | xxxxxxxx xxxxxxxx |
| 0001 0000-0010 FFFF | xxxxxxxxxx yyyyyyyyyy + 0x10000 | 110110xxxxxxxxxx 110111yyyyyyyyyy |
UTF-16编码最明显的优点是它在存储效率上比UTF-32高两倍,因为每个字符(BMP字符)只需要2个字节来存储,而不是UTF-32中的4个字节。
UTF-8
无论是UTF-32还是UTF-16,一个Unicode字符都需要多个字节来编码,这对那些使用英语的国家来说很浪费存储空间和传输带宽。由此,UTF-8产生了。在UTF-8编码中,ASCII码中的字符还是ASCII码的值,只需要一个字节表示,其余的字符需要2字节、3字节或4字节来表示。因此,它是一种变长的编码方式。UTF-8是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式如UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示)在互联网上基本不用。
UTF-8 的编码规则很简单,只有二条:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
- 对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x、y、z、w表示可用编码的位。
| Unicode符号范围 (十六进制) | Unicode 码位 (二进制) | UTF-8编码 (二进制) |
|---|---|---|
| 0000 0000-0000 007F | xxxxxxx | 0xxxxxxx |
| 0000 0080-0000 07FF | xxxxxyyyyyy | 110xxxxx 10yyyyyy |
| 0000 0800-0000 FFFF | xxxxyyyyyyzzzzzz | 1110xxxx 10yyyyyy 10zzzzzz |
| 0001 0000-0010 FFFF | xxxyyyyyyzzzzzzwwwwww | 11110xxx 10yyyyyy 10zzzzzz 10wwwwww |
根据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。UTF-8的编码存储空间更合理,但是进行编码或解码的效率降低了,这就是所谓的用时间换空间。
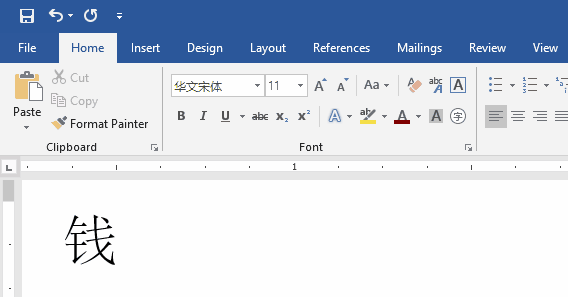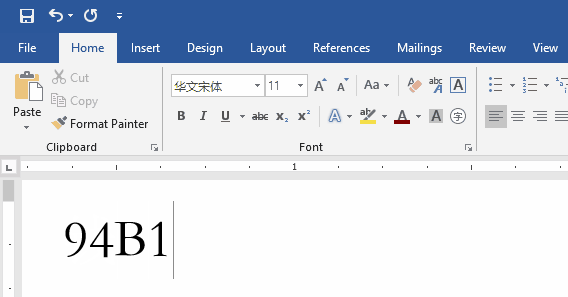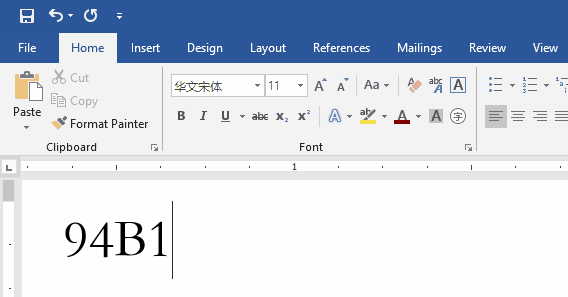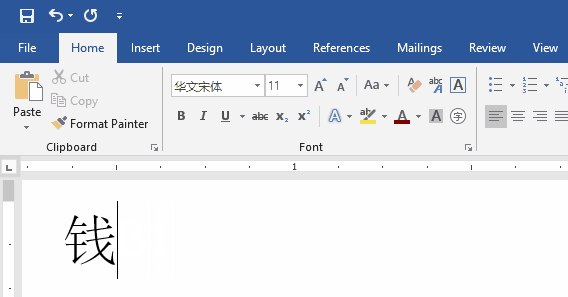
下面以汉字钱为例,演示如何计算 UTF-8 编码。
钱字的Unicode码为U+94B1,根据上表,可以发现94B1处在第三行的范围内,因此钱的 UTF-8 编码需要三个字节,即格式是1110xxxx 10yyyyyy 10zzzzzz。94B1的二进制为1001 0100 1011 0001,从最后一个二进制位开始,将其分成6-6-4三组,分别填入格式中的x、y、z中,不足的位补0。这样就得到了钱的 UTF-8 编码是11101001100100 101011 0001,转换成十六进制就是E992B1。
我们可以通过文本编辑器来验证下计算结果:

Unicode的实现方式还包括 UTF-7、CESU-8、SCSU、GB18030 等,这些实现方式有些仅在一定的国家和地区使用,有些则属于未来的规划方式。当前通用的实现方式是 UTF-16 小端序(LE)、UTF-16 大端序(BE)和 UTF-8。当前辅助平面的工作主要集中在第二和第三平面的中日韩统一表意文字(CJK Unified Ideographs)中,因此包括 GBK、GB18030、Big5等简体中文、繁体中文、日文、韩文以及越南喃字的各种编码与 Unicode 的协调性被重点关注。考虑到 Unicode 最终要涵盖所有的字符,从某种意义而言,这些编码方式也可视作 Unicode 的出现于其之前的既成事实的实现方式,如同 ASCII 及其扩展 Latin-1 一样,后两者的字符在 16 位 Unicode 编码空间中的编码第一字节各位全为 0,第二字节编码与原编码完全一致。
由于大部分常用汉字的编码都被分配在
0000 0800-0000 FFFF这个区间,这导致汉字用UTF-8编码会占用3个字节的空间,这使得用UTF-8来存储汉字要比用GB系列的编码多占用50%的存储空间。
Code range (hexadecimal)
UTF-8
UTF-16
UTF-32
GB 18030
00 0000 – 00 007F
1
2
4
1
00 0080 – 00 009F
2
2 for characters inherited from
GB 2312/GBK (e.g. most
Chinese characters) 4 for
everything else.00 00A0 – 00 03FF
00 0400 – 00 07FF
00 0800 – 00 3FFF
3
00 4000 – 00 FFFF
01 0000 – 03 FFFF
4
4
4
04 0000 – 10 FFFF
BOM
字节顺序,又称端序或尾序(Endianness)。在计算机科学中,它是指多字节对象在内存中的存放顺序。
- big-endian(大端序,BE):地址存放最高有效字节(Most Significant Byte,MSB)
- little-endian(小端序,LE):低地址存放最低有效字节(Least Significant Byte,LSB)
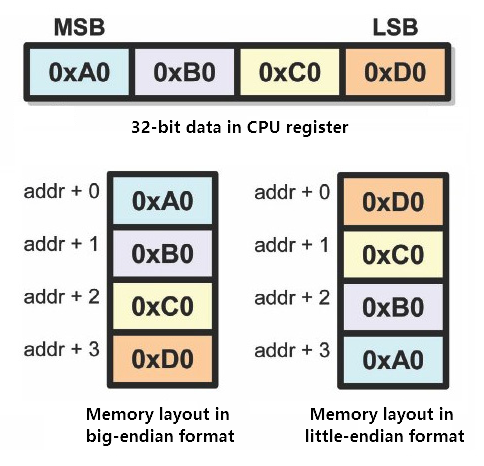
字节顺序属于数据解释的方式,和处理器架构有关。IBM的PowerPC系列CPU采用big-endian方式存储数据;Intel的x86系列则采用little-endian方式存储数据;而ARM系列的CPU则可以使用跳线来配置字节顺序。
关于big-endian与little-endian的更多信息,我会在后续的文章中再详细阐述。
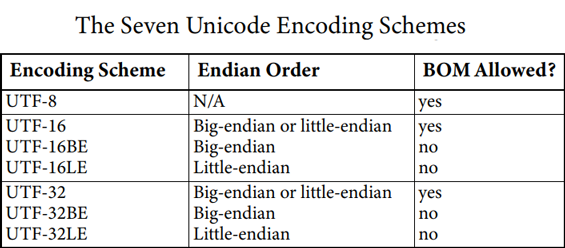
BOM(byte order mark,字节顺序标记)是为 UTF-32 和 UTF-16 设计的,用于标记字节顺序(byte order)的一种技术方案。UTF-8 不需要 BOM,但Unicode 标准允许在 UTF-8 中使用 BOM。
| BOM | 编码格式 |
|---|---|
| EF BB BF | UTF-8 |
| FE FF | UTF-16/UCS-2, big endian |
| FF FE | UTF-16/UCS-2, little endian |
| 00 00 FE FF | UTF-32/UCS-4, big-endian |
| FF FE 00 00 | UTF-32/UCS-4, little endian |
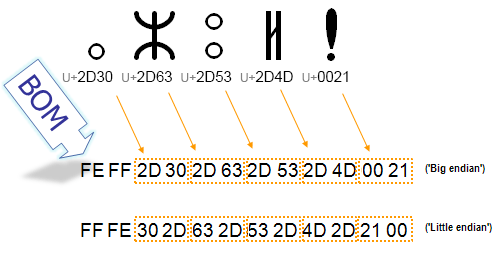
- 编码U+FEFF如果出现在字节流的开头,则用来标识该字节流的字节序为大端序。如果它出现在字节流的中间,则表示为
零宽度非换行空格(zero width no-break space),用户看起来就是一个空格。从Unicode3.2开始,U+FEFF只能出现在字节流的开头,只能用于标识字节序;除此以外的用法已被舍弃。取而代之的是使用U+2060来表达零宽度非换行空格。 - 编码
U+FFFE没有对应到任何Unicode字符,即该码位没有被分配,它只能出现在字节流的开头,表示小端序。
为什么UTF-8不需要BOM
这个问题一直萦绕在我的心头。我查阅过很多资料,但感觉都没能说明白这个问题,下面的论述是我自己对这个问题的理解。
这个问题的根源在于计算机软件是如何读取字符的。我们知道,无论是读取存在于文件中的字符,还是通过网络传输过来的字符,这些数据都会在先暂存在内存中,形成字节流/序列(byte stream)。流这个概念很重要,它表示字节是是没有分割的。那么问题来了,软件要如何分割这些连续的字节流,从而转换成我们人可以看得懂的字符流呢?
首先软件需要知道当前字节流的编码。这个编码可以是由用户自行选定或者软件默认定义,也可以从一些元数据那里知道(例如HTTP请求头中的charset会指示HTTP内容的编码)。
- 如果当前的编码是ASCII,那么软件会一次读取1个字节,将其转换成对应的ASCII字符,这就OK了。因此ASCII编码和BOM没有任何关系。
- 如果当前的编码是UTF-16,因为UTF-16是2个字节或4个字节构成一个字符,因此软件会一次读取2个字节。这个时候问题又来了,这2个字节该怎么解析呢?它用的是大端序还是小端序?哪一个字节用作高位,哪一个用作低位?此时,BOM就发挥作用了。
- 对于UTF-32编码,软件会一次读取4个字节,与UTF-16同理,需要BOM来指示如何解析这4个字节。
- 然而对于UTF-8,情况则完全不同。因为UTF-8是变长字节编码,因此当软件准备解析一个字符时,会先顺序读取第1个字节,然后决定是停止当前字符的解析(当字符在ASCII范围内),还是继续顺序读1个、2个或者3个字节。简而言之,UTF-8的编码有着严格的字节序,它只能有一种形式,否则就是错误的编码。
- 如果
编码的名称已经规定了BOM,例如UTF-32BE、UTF-32LE、UTF-16BE或UTF-16LE,那么BOM是不需要的,而且Unicode标准规定在这种情况下禁止提供BOM。 - 显而易见的是,当用户或软件选错了编码,那么解析出来的字符序列就是乱码。
UTF-8 不需要 BOM,但Unicode 标准允许在 UTF-8 中使用 BOM。所以不含 BOM 的 UTF-8 才是标准形式,在 UTF-8 文件中放置 BOM 主要是微软的习惯(顺便提一下,把带有 BOM 的小端序 UTF-16 称作「Unicode」而又不详细说明,这也是微软的习惯)。微软在 UTF-8 中使用 BOM 是因为这样可以把 UTF-8 和 ASCII 等编码明确区分开,但这样的文件在 Windows 之外的操作系统里会带来问题。例如在Linux系统中,BOM会妨碍到脚本开头的Shebang等的一些重要代码的正确处理。它亦会影响到无法识别它的编程语言。如gcc会报告源码档开头有无法识别的字符。Windows 的记事本有个毛病就是在 UTF-8 文件开头加 BOM,所以不要用记事本来编辑UTF-8 文件。使用 UTF-8 编码的网页代码不要使用 BOM,否则会容易出错。字节顺序标记在UTF-8中被表示为序列EF BB BF,对大部分未准备好处理UTF-8的文本编辑器及网页浏览器而言,在ISO-8859-1的环境中则会显示
。
According to the Unicode standard, the BOM for UTF-8 files is not recommended:
Use of a BOM is neither required nor recommended for UTF-8, but may be encountered in contexts where UTF-8 data is converted from other encoding forms that use a BOM or where the BOM is used as a UTF-8 signature.
In the UTF-8 encoding, the presence of the BOM is not essential because, unlike the UTF-16 encodings, there is no alternative sequence of bytes in a character. However, the BOM may still occur in UTF-8 encoded text, either as a by-product of an encoding conversion or because it was added by an editor to flag the content as UTF-8. In this situation, the BOM is often called a UTF-8 signature.
如何查找字符的Unicode码位
如果想要知道某个字符的Unicode编码值,有没有什么简单的办法?答案是肯定的。
https://graphemica.com 可以搜索任意字符,搜索结果包含Unicode编码值及相关的信息。
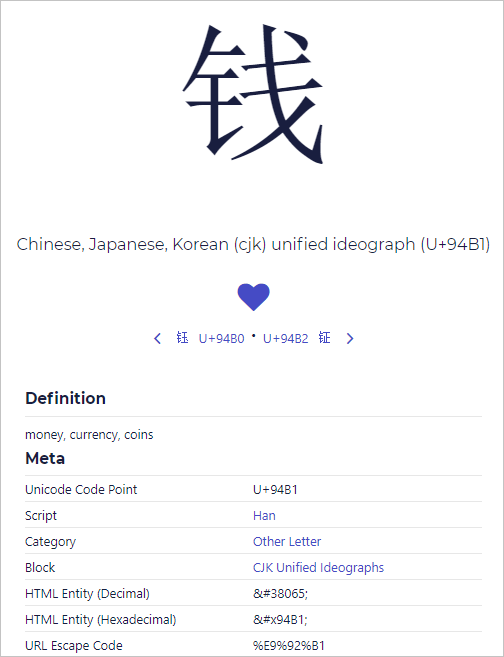
如果要查询的是汉字,则可以使用汉典。
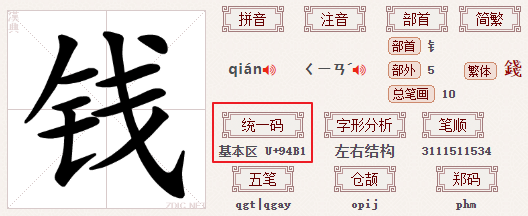
在Word中按
Alt + X组合键,Word会将光标前面的字符与其Unicode 编码值进行相互转换。