字符编码与字符集 — 中文字符集
计算机发明之后的很长一段时间只应用于美国及西方一些国家,ASCII字符集以及EASCII能够很好的满足需求。在上个世纪80年代,当计算机开始引入中国时,面临的一个大难题是中文的显示与处理,而首要任务就是要针对汉字制定一套自己的编码规范。
GB 2312
GB 2312 或 GB 2312-1980 是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称 GB0,由中国国家标准总局1980年3月发布,于1981 年 5 月 1 日实施。GB 2312 编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312。
GB 为“国标”的汉语拼音首字母缩写,即“国家标准”之意。强制标准冠以“GB”,推荐标准冠以“GB/T”,指导性技术文件冠以“GB/Z”。目前GB 2312是推荐标准,其后继者GB 18030已成为简体中文字符集的强制标准。我以前特别好奇2312有什么含义,后来才发现这只是国家标准的编号而已。在全国标准信息公共服务平台上可以查询到GB 2312-80的详细信息。

GB 2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。但对于人名、古汉语等方面出现的罕用字和繁体字,GB 2312不能处理,因此后来GBK及GB 18030汉字字符集相继出现来解决这些问题。
GB 2312编码方案
区位码
GB 2312对所收录的字符进行“分区”处理,每区含有94个汉字/符号,共计94个区,它是一个94×94的表格,理论上有94×94=8836个空间。每个字符可以由所在的区和位来唯一确定。区码和位码分别占用一个字节,每个字节均采用七位编码表示,均从1开始编号。这种编码方式称为区位码。
- 01~09区(682个):特殊符号、数字、英文字符、制表符等,包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等在内的682个全角字符;
- 10~15区:空区,留待扩展。
- 16~55区(3755个):常用汉字(也称一级汉字),按拼音字母排序;
- 56~87区(3008个):非常用汉字(也称二级汉字),按部首笔画排序;
- 88~94区:空区,留待扩展。
一个字节有128个空间,128-32=96,实际上,ASCII中第127个也是控制码(DEL,删除),再减去就还有95个有效位,再加上区位从1开始,又损失了一位,所以最终只有94个有效位了,这也是前面为何是一个94×94的表格。
按照一个字符所占用字节的个数,字符集可以分为:
- 单字节字符集(single-byte character set, SBCS)。在这种编码模式下,所有的字符都只用一个字节表示,ASCII是SBCS。一个字节表示的0用来标志SBCS字符串的结束。
- 多字节字符集(multi-byte character set,MBCS)。一般以双字节字符(double-byte character set,DBCS)居多。中文字符以及大多数的东亚文字都是双字节字符。
国标码
ASCII字符集中的前32个字符是控制码,中文系统自然也不能少了这些控制码。为了避免与这些控制码相冲突,GB 2312规定编码范围为十六进制(21,21)(7E,7E),十进制(33,33)(126,126),将“区码”和“位码”分别加上32(十六进制为20H)后的结果作为国家标准代码,简称国标码。自GB 2312公布以来,我国一直延用该标准所规定的国标码作为统一的汉字信息交换码。
机内码
国标码的定位是与ASCII一致的,是作为国家信息交换的标准码。从设计上看,它并没打算兼容ASCII,因为它已经把ASCII中的可显示字符(英文字母+数字,33~126)都收录了过来,重新以两字节编码,即所谓的全角字符(全角字符在屏幕上的显示宽度为ASCII字符的两倍,后来也因此而将对应的ASCII字符称之为半角字符),而全角字符显示效果其实是很差的。最终,一种能兼容ASCII的存储方案得到了广泛采纳,这就是所谓的机内码了。
将国标码高低字节分别加上0x80(128)就得到了机内码(有时又叫交换码)。128的二进制形式为10000000,加128,简单地讲,就是把国标码两个字节的最高位都置成1。国标码加128后,高低字节的最高位都成了1,而ASCII码的最高位为0,这样就能与ASCII码区分开来。这种方案又称为EUC-CN,是GB 2312最常用的表示方法。浏览器编码表上和一些文本编辑器中的“GB2312”,通常都是指“EUC-CN”表示法。
三种编码之间的关系如下:

虽然我们常把GB 2312称为国标码,但我们应该清楚,实际存储使用的是机内码,通常说到GB 2312编码时指的就是这个机内码了。它能兼容ASCII,是一种变长的编码方案,对ASCII中的字符(也即所谓的“半角西文字符”)采用一字节编码,最高位为0;对区位表中的字符采用双字节编码,且每字节最高位均为1。下面是一个混合了汉字啊,全角字母a和半角字母a的编码示例,共5个字节:

直接向计算机输入区位码而得到汉字的方法叫做
区位输入法。相应地,输入机内码而得到汉字的方法叫做GB内码输入法。在DOS时代,许多中文系统都实现了机内码及区位码输入法。在DOS被Windows系统取代后,拼音输入法、五笔输入法成为了主流的中文输入法,机内码和区位码输入法就很少有人使用了。Windows XP中还有机内码和区位码输入法,但到了Windows Vista就被移除了。我们将在后续的文章中探讨关于输入法的一些概念和问题。
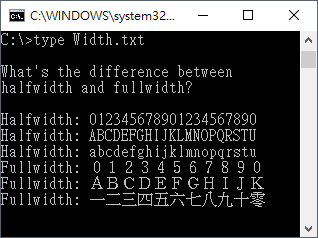
全角/半角
全角字符是中文显示及双字节中文编码的历史遗留问题。
早期的点阵显示器上由于像素有限,原先ASCII西文字符的显示宽度(比如8像素的宽度)用来显示汉字有些捉襟见肘(实际上早期的针式打印机在打印输出时也存在这个问题),因此就采用了两倍于ASCII字符的显示宽度(比如16像素的宽度)来显示汉字。这样一来,ASCII西文字符在显示时其宽度为汉字的一半。或许是为了在西文字符与汉字混合排版时,让西文字符能与汉字对齐等视觉美观上的考虑,于是就设计了让西文字母、数字和标点等特殊字符在外观视觉上也占用一个汉字的视觉空间(主要是宽度),并且在内部存储上也同汉字一样使用2个字节进行存储的方案。这些与汉字在显示宽度上一样的西文字符就被称之为全角字符。而原来ASCII中的西文字符由于在外观视觉上仅占用半个汉字的视觉空间(主要是宽度),并且在内部存储上使用1个字节进行存储,相对于全角字符,因而被称之为半角字符。
后来,其中的一些全角字符因为比较有用,就得到了广泛应用(比如全角的逗号“,”、问号“?”、感叹号“!”、空格“ ”等),专用于中日韩文本,成了标准的中日韩标点符号。而其它的许多全角字符则逐渐失去了应用价值(现在很少需要让纯文本的中文和西文字符对齐了),就很少再用了。
Windows命令提示符中显示的全角和半角字符
汉卡
早期的计算机运算能力非常弱,而 GB 2312 的编码规则无形中又给解码增加了额外负担,所以为了提高汉字的输入性能,一种叫 “汉卡” 的硬件出现了,它直接负责 GB 2312 的编解码,为 CPU 分担任务。
GB 13000
在总结了 GB 2312 的种种缺陷后, 国家标准化委员会又制定了GB 13000, 虽然它也是双字节字符集,但与 GB 2312 完全不同,它参照了 Unicode 标准,也就是说 GB 13000 是面向国际化的,但这也直接导致了它不兼容 GB 2312,之后逐渐沦为了 “纸面上的标准”。
GBK
GBK,全名为《汉字内码扩展规范(GBK)》1.0版。GBK的K为“扩展”的汉语拼音(kuòzhǎn)第一个声母。英文全称Chinese Internal Code Extension Specification。GBK 只为“技术规范指导性文件”,不属于国家标准,只是一个事实上的标准。国家质量技术监督局于2000年3月17日推出了GB 18030-2000标准,以取代GBK。
GBK是微软对GB 2312-80的扩展,也就是对CP936代码页(Code Page 936)的扩展(CP936和GB 2312-80是对应的),最早实现于Windows 95简体中文版。虽然GBK收录GB 13000的全部字符,但GBK是一种
编码方式并向下兼容GB2312;而GB 13000等同于Unicode 1.1是一种字符集,它的几种编码方式如UTF8、UTF16LE等,与GBK完全不兼容。
GBK跟GB 2312一样是双字节编码,但GBK只要求第一个字节即高字节是大于127就固定表示这是一个汉字的开始(0~127当然表示的还是ASCII字符),不再要求第二个字节即低字节也必须是127号之后的编码。这样,作为同样是双字节编码的GBK才可以收录比GB2312更多字符。GBK字符集向后完全兼容GB2312,还支持GB 2312不支持的部分中文简体、中文繁体、日文假名,还包括希腊字母以及俄语字母等字母,共收录汉字21003个、符号883个,并提供1894个造字码位,简体字与繁体字融于一体。
GB 18030
GB 18030全称《信息技术·中文编码字符集》,是变长多字节字符集。其对GB 2312-1980完全向后兼容,与GBK基本向后兼容(只有很少几处不同),并支持Unicode(GB 13000)的所有码位。GB 18030共收录汉字70,244个。
GB 18030主要有以下特点:
- 采用变长多字节编码,单字节的ASCII、双字节的GBK(略带扩展)、以及用于填补所有Unicode码位的四字节UTF区块。
- 编码空间庞大,最多可定义161万个字符。
- 完全支持Unicode,无需动用造字区即可支持中国国内少数民族文字、中日韩和繁体汉字以及emoji等字符。
GB 18030的当前版本为GB 18030-2005,2006年5月1日实施;是在GB 18030-2000基础上增加了CJK统一汉字扩充B的汉字。而GB 18030-2000则是在GBK的基础上增加了CJK统一汉字扩充A的汉字。
Windows系统下你可能要安装GB 18030的相关插件才能处理及显示那些增补的字符,一般系统默认情况也不会安装能支持完整显示GB 18030全体字符的字体。GB 18030的变长多字节编码给软件处理带来了难度,即使作为一个强制标准,但无论是操作系统还是各种应用软件,都没能对GB 18030有很好地支持。GB 18030在Windows系统中对应的代码页为
Code Page 54936。
总结
本文介绍了GB系列的中文字符编码与字符集,相关的文件可以在我的github上找到。