字符编码与字符集 — 西文字符集
众所周知,现代的信息技术都是构建在二进制的基础之上。你所看到的文字、符号、图像、语音、视频等等在计算机、手机等设备内部都是以0、1的形式存在和存储的。如此缤纷多彩的计算机和网络世界却只是由0、1这两种元素构成,真有点「道生一,一生二,二生三,三生万物」的意味。
字符编码
文字和符号可以简称为字符。在计算机中,英语字母(拉丁字母)、阿拉伯数字、汉字、标点符号等等以及一些不可见的控制符号都是字符。这么多的字符,是如何用简单的0和1来表示呢?
其实在计算机的内部,有一部虚拟的“字典”。它记录着用0和1代表的二进制数字与字符的映射关系。用计算机的术语,这个“字典”叫字符编码表。具体用哪个二进制数字表示哪个符号,每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码。
字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符集(Charset)是多个字符的集合。
字符编码(Character Encoding)是把字符集中的字符按一定格式编码为某指定集合中某一对象(比如由0和1两个数字所组成的二进制串、由0~9十个数字所组成的自然数序列、电脉冲等)的过程,即在字符集与指定集合之间建立一个对应关系(映射关系)的过程。它是信息处理的一项基本技术。
码位(Code Point)或称编码位置,是组成编码空间的数值。例如,ASCII码包含128个码位,范围是0x00到0x7F;扩展ASCII码包含256个码位,范围是0x00到0xFF;而Unicode包含1,114,112个码位,范围是0x00到0x10FFFF。
ASCII
现代信息技术都是西方科技发展的产物。在计算机刚发明的年代,美国国家标准学会(American National Standard Institute , ANSI )最先制定了一套编码方案。他们决定用8 bit来表示一个字符,这样一共可以表示256种字符。对于英语来说,26个字母、10个阿拉伯数字加上一些符号,256个位置已经足够了。它们的映射关系是:
- 0 – 31 以及 127 分给了一些有特殊功能的不可见字符(如换行、换页、退格、移至行首等等)
- 32 – 126 分给了可见字符,其中48-57为阿拉伯数字,65-90为大写字母,97-122为小写字母,其余为标点、百分号、加减乘除等
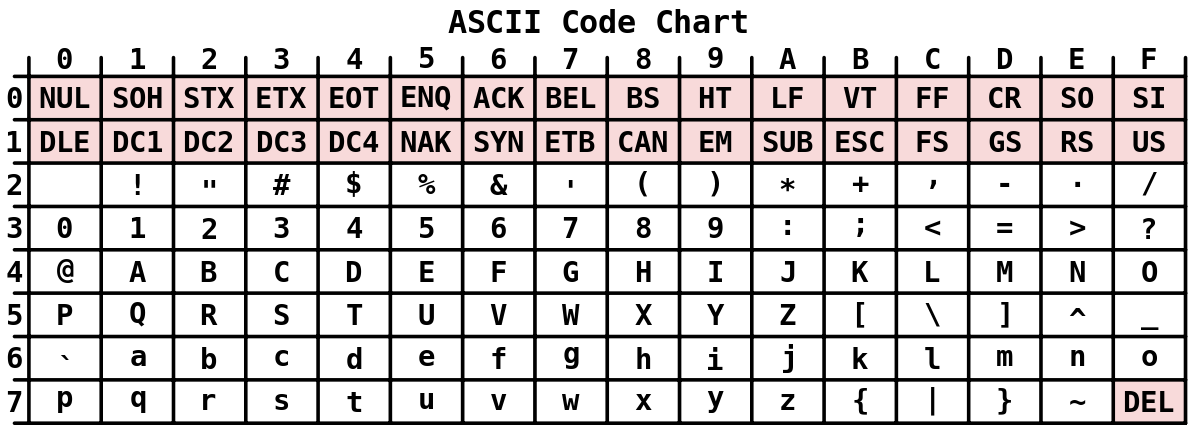
这套映射关系被命名为 ASCII 编码(American Standard Code for Information Interchange,美国信息交换标准代码)。
ASCII第一次以规范标准发表是在1967年,最后一次更新则是在1986年,迄今为止一共定义了128个字符;其中33个字符无法显示,且这33个字符多数都已是陈废的控制字符。控制字符的用途主要是用来操控已经处理过的文字。在33个字符之外的是95个可见的字符。用键盘敲下空白键所产生的空白字符(ASCII码为32)也算1个可见字符(显示为空白)。ASCII码只占用了1个字节的前7位,并预留一位做扩展,或用作奇偶校验。
ASCII 码后来被国际标准化组织(International Organization for Standardization, ISO)定为国际标准,称为ISO/IEC 646。
EASCII
随着计算机的流行,其他使用拉丁字母语言(主要是欧洲国家)的人发现ASCII码中定义的128个字符不够用。比如,拉丁文中有很多带有音符的字母,比如á、â、ã、ä;希腊字母α、ß、π等,这些字符就不能用ASCII码来表示了。
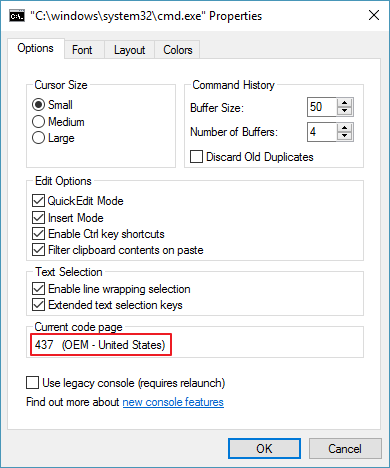
于是人们开始考虑ASCII码中127号之后的区域。前文说了,ASCII码中只有前7位(128个字符)是国际标准,而后边128个位置并没有做出规定或限制。基于这后边的128个位置制定的编码称为ASCII扩展码(EASCII,Extended ASCII),它不是国际标准,也不可能是国际标准,因为每个国家都有自己的需求。但位置又只有128个,于是各个国家与公司竞相推出自己的标准。其中用的比较广的可能要算IBM扩展字符集了,也就是 Windows 系统使用的Code Page 437字符编码。

一些终端提供了扩展,使得标准ASCII码中的不可见字符可显示为诸如笑脸、扑克牌花式等符号。
Code Page 437也是Windows命令行程序默认的字符集,这也是默认的命令行程序不能显示中文的原因。
ISO/IEC 8859
为了解决各国各语言对ASCII进行扩展编码的混乱局面,国际标准化组织制定了ISO 8859字符集。其下共包含了15个字符集,即ISO/IEC 8859-n,其中n=1,2,3,…,15,16(其中12未定义,所以共15个)。这15个字符集大致上包括了欧洲各国所使用到的字符(甚至还包括一些外来语字符),而且每一个字符集的补充扩展部分(即除了兼容ASCII字符之外的部分)都只实际使用了0xA00xFF(十进制为160255)这96个编码。其中,ISO/IEC 8859-1收录了西欧常用的字符(包括德法两国的字母),目前使用得最为普遍。
各种ISO 8859字符集
- ISO/IEC 8859-1 (Latin-1) - 西欧语言
- ISO/IEC 8859-2 (Latin-2) - 中欧语言
- ISO/IEC 8859-3 (Latin-3) - 南欧语言。世界语也可用此字符集显示。
- ISO/IEC 8859-4 (Latin-4) - 北欧语言
- ISO/IEC 8859-5 (Cyrillic) - 斯拉夫语言
- ISO/IEC 8859-6 (Arabic) - 阿拉伯语
- ISO/IEC 8859-7 (Greek) - 希腊语
- ISO/IEC 8859-8 (Hebrew) - 希伯来语(视觉顺序)
- ISO 8859-8-I - 希伯来语(逻辑顺序)
- ISO/IEC 8859-9(Latin-5 或 Turkish)- 它把Latin-1的冰岛语字母换走,加入土耳其语字母。
- ISO/IEC 8859-10(Latin-6 或 Nordic)- 北日耳曼语支,用来代替Latin-4。
- ISO/IEC 8859-11 (Thai) - 泰语,从泰国的 TIS620 标准字集演化而来。
- ISO/IEC 8859-13(Latin-7 或 Baltic Rim)- 波罗的语族
- ISO/IEC 8859-14(Latin-8 或 Celtic)- 凯尔特语族
- ISO/IEC 8859-15 (Latin-9) - 西欧语言,加入Latin-1欠缺的芬兰语字母和大写法语重音字母,以及欧元(€)符号。
- ISO/IEC 8859-16 (Latin-10) - 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号。
由于英语没有任何重音字母,故可使用以上十五个字集中的任何一个来表示。
对于德语而言,因它除了A-Z, a-z外,只用 Ä, Ö, Ü, ä, ö, ß, ü 七个字母,而所有拉丁字集(1-4, 9-10, 13-16)均有此七个字母,故德语可使用以上十个字集中的任何一个来表示。
此系列中没有-12号的原因是,计划原本要设计成一个包含塞尔特语族字符集的“Latin-7”,但后来塞尔特语族变成了ISO 8859-14 / Latin-8。亦有一说-12号本来是预留给印度天城体梵文的,但后来却搁置了。
ISO 8859是在1980年代中期甚至1990年代才陆续公布的。但是微软公司与IBM公司等此前已经在其产品,如MS-DOS, IBM PC上使用了各自定义的编码字符集(即“代码页”, Code Page)。ISO 8859公布后,也出现了一些广泛使用的代码页,它兼容并扩充了ISO 8859。例如,
Code Page 1252作为英文及一些西欧语言版Windows操作系统的默认编码(locale),是ISO 8859-1的超集。点击这里查看全部的Code Page